Q&A Report: Towards Automated Spikesorting using Artificial Intelligence on a Cloud-Based Platform
These answers were provided by:
Fan Wu, PhD
Vice President
Product Development
Diagnostic Biochips
Lidor Spivak, MA
PhD student
Sagol School of Neuroscience
Tel-Aviv University
What types of electrodes and acquisition systems do you support? What format does data need to be exported in?
Currently, we support raw data (.dat) acquired by Intan or OpenEphys systems. Other data types can currently be reformatted into the .dat format offline before upload. In the future, we will also consider supporting other formats as standard options. DBCloud is also electrode agnostic: besides all of DBC’s product line, we also support data from Neuropixel, tetrode, EEG, sEEG, HD-MEA, etc.
In a high frequency signal involving multiple action potentials, how would you recommend minimizing the risk of action potential waveforms that overlap or coincide close enough in time to distinguish them from each other?
Kilosort, by means of template matching, is a great tool for separating superimposed waveforms. Additionally, using high-density recording site arrangement from a typical Diagnotic Biochips probe also adds multiple dimensions that can help to separate the units.
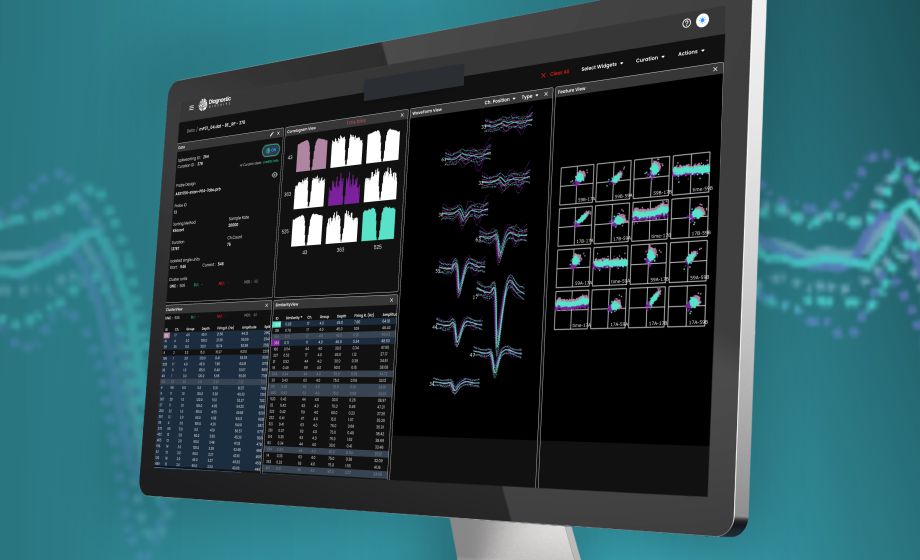
Despite the recent growth of automatic spike sorting tools, a great proportion of researchers still do it manually. Why does this happen?
High-density electrophysiology recordings are complex, and spikesorting quality is difficult to evaluate without widely accepted metrics or ground truth. Each lab ends up developing its own custom solutions for its unique set of challenges. With DBCloud, we see two possible scenarios to address this challenge using AI. The goal is to create an AI model that does as well as the experimenters. 1) we use a large and diverse set of data to train a universal AI model that can be generalized for all data. This will be the most challenging approach. 2) In contrast to the first approach, we hypothesize that all data acquired from one particular lab will have similarities in terms of animal model, brain region, cell types, recording SNR, and sorting techniques, that are generalizable within that lab but not for other labs. Therefore, we can use DBCloud to train a very specific or tailored AI model to automate spikesorting for that lab. Again, a presumption is that automation can be utilized as long as the algorithm does as well as the researchers subjectively.
What is your plan for applying your probe and software technologies to preclinical drug screening?
High-density neural probes can record multi-dimension, timeseries data in freely behaving animals. These recordings have been shown to contain biomarkers such as mean spike firing rate and power from various local field potential (LFP) bands from multiple brain regions that are modulated by candidate drugs. However, the current methods to extract these biomarkers are subject to custom preprocessing techniques, thresholding criterion, and therefore lack repeatability and throughput. Additionally, there might exist features in these complex timeseries that have yet to be identified but can be more strongly correlated with the drug effects. We plan to combine massive, high-density neural data with advanced machine learning techniques such as self-attention, temporal modeling, and deep neural network that are uniquely suited to train predictive models.
What are the features that the AI classifiers uses for training and predicting? And is it agnostic to the type of spikesorter used?
The AI classifiers are trained using correlograms and mean waveforms derived from human-labeled units. While they are agnostic to the type of spike sorter employed, their performance may be impacted by the differences between spike sorters. Some spike sorters tend to over-cluster the data, while others may under-cluster. These discrepancies can affect the shapes of correlograms (over-clustering often results in correlograms with clean auto refractory periods) and waveforms, ultimately influencing the AI classifier’s performance. In general, a classifier trained on a specific spike sorter will perform better when used with the same sorter.
Can the automated curator split units in addition to merging units?
Currently, the automated curator can only merge units. On DBCloud, we’ve built in default spikesorter parameters to encourage oversplitting clusters that are much more likely to require merging than splitting.
Can the spike sorter AI keep track of what happens to a specific cluster of spikes before and after treatment? For example, by linking amplitude and timing, to answer the question of whether this cell has decreased or increased in firing rate due to treatment such as in an MEA setting?
The AI can effectively track specific neurons across various treatments if the effects of the manipulation transpire gradually over time. Generally, a typical spike sorter may split the spikes of a given unit during treatment. If these split units can be merged by examining their mean waveforms and cross-correlograms (CCHs), then the AI can also merge these units.
Can this sorter handle multi-session data and identify units that appear on several recordings?
It is possible to concatenate multiple sessions and then run spikesorting. However, most of our users currently treat units from different sessions as separate units.
My interest is in finding software that can help us overcome our lack of expertise. We have performed many MEA recordings and had to stop because we lacked confidence in our abilities to appropriately sort the recorded spikes, and we've had difficulty finding the time/outside experts to train us. If we do not personally have the knowledge to perform our own manual spike sorting, can this software make up the difference?
Yes, DBCloud is designed to automate and reduce the level of required expertise to properly run analytical processes such as spikesorting. We also provide consultation and spikesorting service.